机构名称:
¥ 2.0
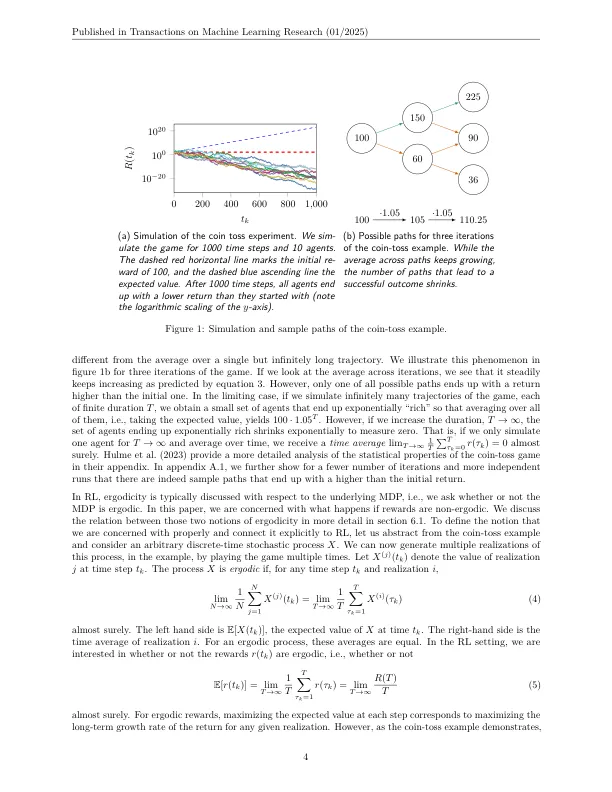
设想的增强学习应用领域(RL)包括自动驾驶,精确农业和金融,所有这些都要求RL代理在现实世界中做出决定。在这些领域中采用RL方法的一项重大挑战是常规算法的非舒适性。尤其是RL的焦点通常是回报的预期值。期望值是无限多个轨迹的统计集合的平均值,这可能对平均个体的性能不信息。例如,当我们具有重尾回报分布时,整体平均值可以由罕见的极端事件主导。因此,优化期望值可能会导致策略,该政策产生了异常高回报,概率
用非依恋奖励增量的加强学习
主要关键词




相关文件推荐