机构名称:
¥ 1.0
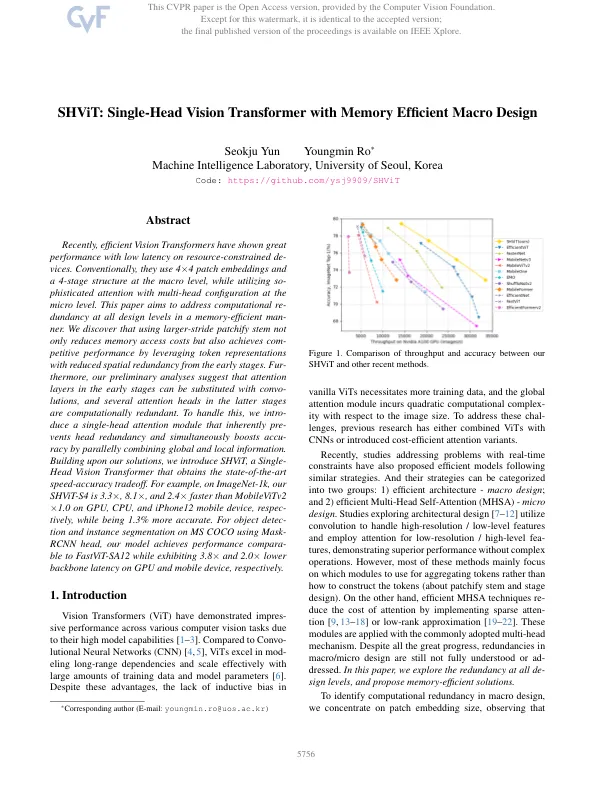
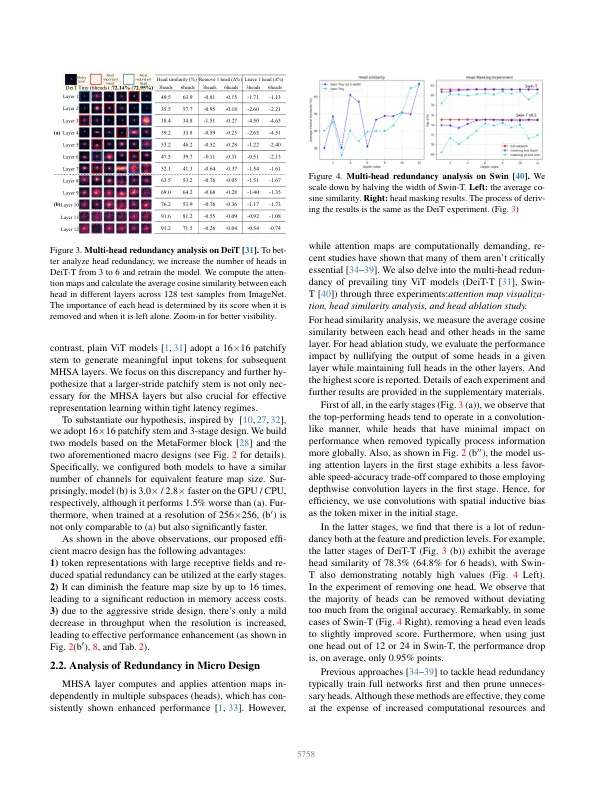
最近,有效的视觉变压器表现出出色的性能,并且在资源受限的范围内延迟较低。通常,他们在宏观水平上使用4×4贴片嵌入式和4阶段结构,同时在微观级别利用多头配置的同时注意力。本文旨在解决记忆效率高的人中所有设计级别的计算重复。我们发现,使用较大的修补茎不仅降低了内存访问成本,而且还通过利用令牌表示,从早期阶段降低了空间冗余,从而实现了态度性能。fur-hoverore,我们的初步分析表明,在早期阶段的注意力层可以用会议代替,并且后期阶段的几个注意力头在计算上是多余的。为了处理这一点,我们介绍了一个单头注意模块,该模块固有地预先预先冗余,并同时通过相结合的全局和本地信息来提高准确性。在解决方案的基础上,我们引入了Shvit,这是一种单头视觉变压器,获得了最先进的速度准确性权衡。例如,在ImagEnet-1k上,我们的SHVIT-S4在GPU,CPU和iPhone12移动设备上比MobileVitV2×1.0快3.3×,8.1×和2.4倍,而同时更准确。用于使用Mask-RCNN头对MS Coco进行的对象检测和实例分割,我们的模型分别在GPU和移动设备上表现出3.8×和2.0×下骨架潜伏期时,可以与FastVit-SA12进行比较。
shvit:带有内存有效宏设计的单头视觉变压器
主要关键词



相关文件推荐





























