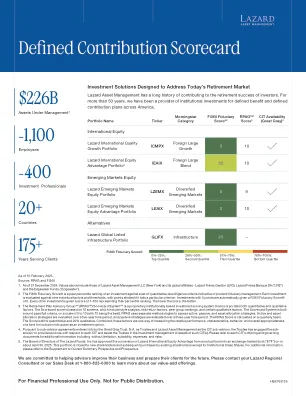
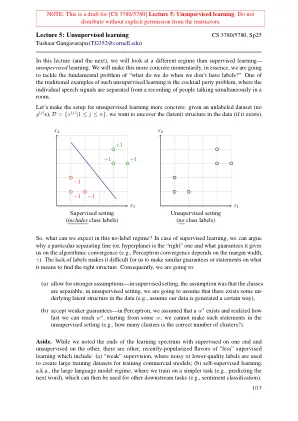
机构名称:
¥ 1.0
最近基于深度学习的多视图人检测(MVD)方法在现有数据集上显示出令人鼓舞的结果。但是,当前方法主要在具有数量有限的多视图框架和固定相机视图的小型单个场景上进行培训和评估。结果,这些方法可能不可行,可以在更大,更复杂的场景中检测出严重的阻塞和摄像机误差错误。本文着重于通过开发有监督的观点加权方法来改善多视图人的检测,该方法可以更好地融合大型场景下的多相机信息。此外,还采用了大型合成数据集来增强模型的概括性,并实现了更实际的评估和比较。通过简单的域适应技术进一步证明了模型在新测试场景上的性能。实验结果证明了我们方法在实现有希望的跨场所多视角人检测表现方面的有效性。
通过监督的视图贡献加权
主要关键词





相关文件推荐