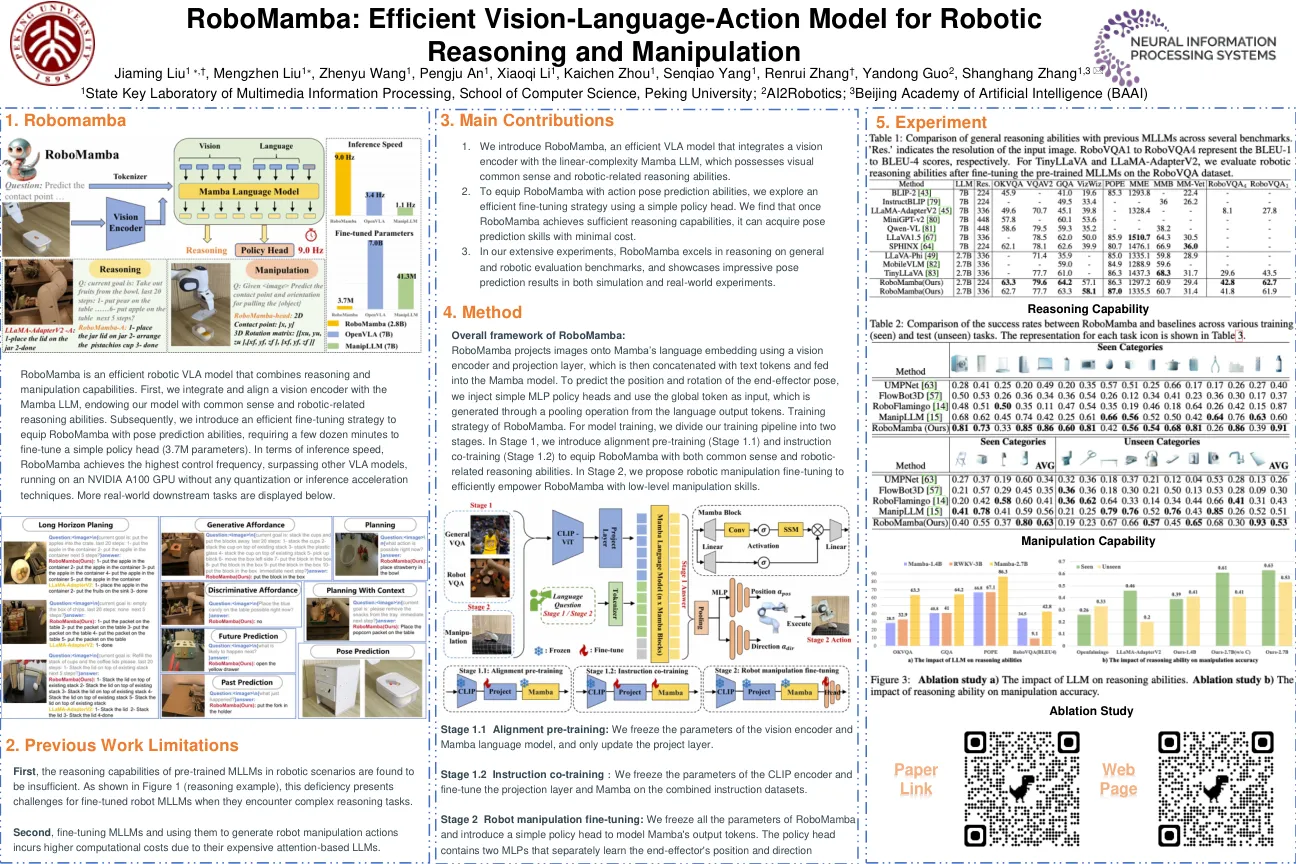
机构名称:
¥ 1.0
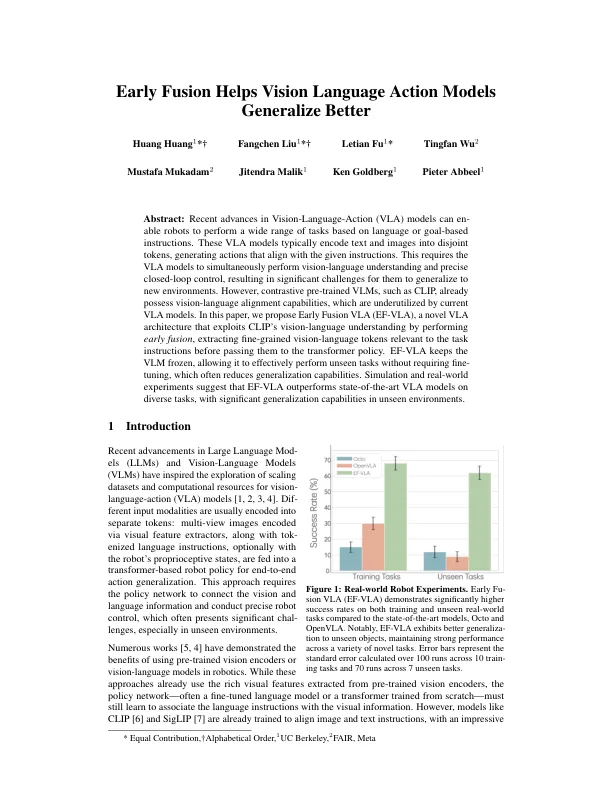
摘要:视觉语言动作(VLA)模型的最新进展可以使机器人根据语言或基于目标的说明执行广泛的任务。这些VLA模型通常将文本和图像编码为脱节令牌,从而生成与给定指令保持一致的动作。这要求VLA模型同时执行视觉语言理解和精确的闭环控制,从而给他们带来重大挑战,以使其概括为新环境。然而,对比的预训练的VLM,例如剪辑,已经具有视觉对齐能力,这些功能被当前的VLA模型未被充分利用。在本文中,我们提出了早期的Fusion VLA(EF-VLA),这是一种新颖的VLA架构,通过执行早期融合来利用Clip的视觉理解,在传递到变压器政策之前,提取与任务指导相关的细粒度视力语言令牌。ef-vla保持VLM冷冻,允许其有效执行看不见的任务而无需进行精细调整,这通常会降低概括能力。仿真和现实世界实验表明,EF-VLA在不同任务上的最先进的VLA模型优于最先进的VLA模型,并且在看不见的环境中具有重要的概括能力。
早期融合有助于视力语言动作模型更好地
主要关键词




相关文件推荐