机构名称:
¥ 1.0
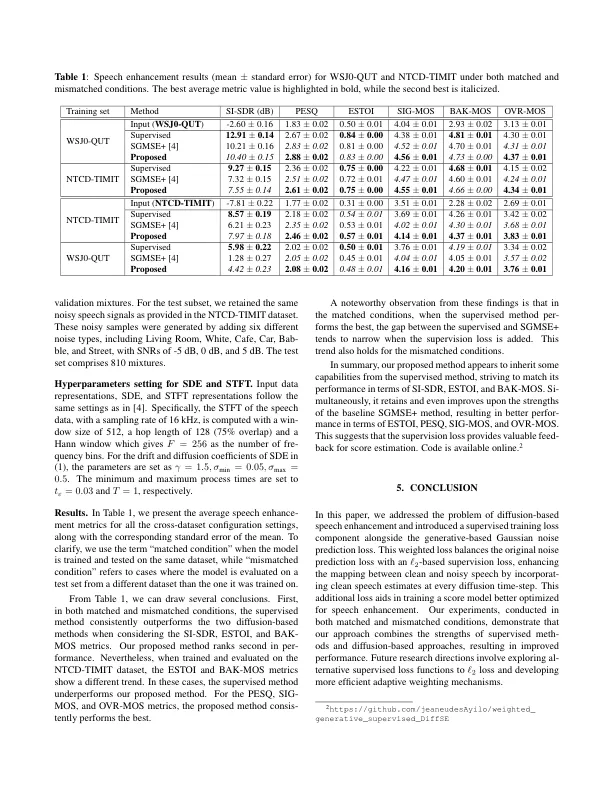
基于扩散的生成模型最近在语音增强(SE)方面获得了研究,为常规监督方法提供了替代方案。这些模型将干净的语音训练样本转化为高斯噪声,通常以嘈杂的语音为中心,随后学习了一个典型的模型以扭转这一过程,从而有条件地在嘈杂的语音上。与受监督的方法不同,基于生成的SE通常仅依赖于无监督的损失,这可能会导致条件嘈杂的语音效率较低。为了解决这个问题,我们提议以ℓ2的损失来增加原始的扩散训练目标,以测量地面真相清洁语音与每个扩散时间阶段的估计之间的差异。实验结果证明了我们提出的方法的有效性。
基于加权的生成性学习损失的基于扩散的语音增强
主要关键词




相关文件推荐