机构名称:
¥ 1.0
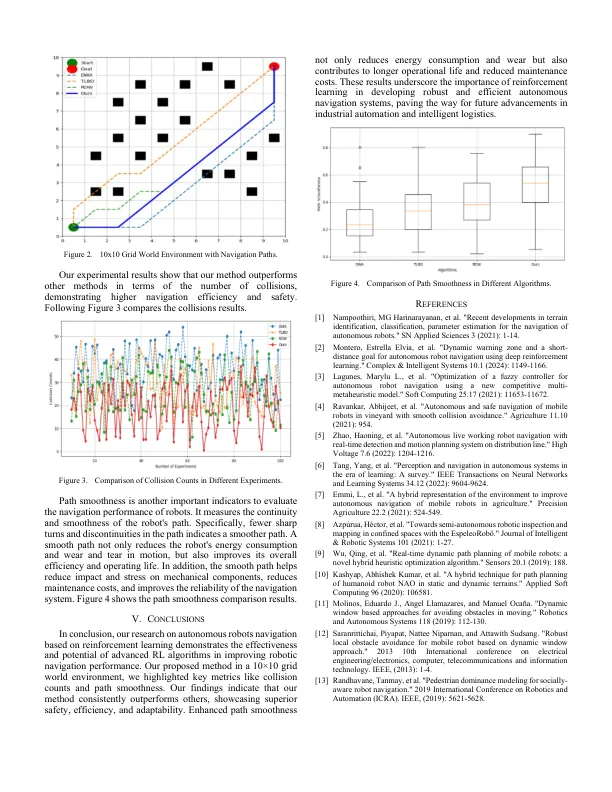
摘要 - 通过与环境的持续互动,基于实时反馈奖励信号不断优化决策,表明了强大的适应性和自学能力。近年来,它已成为实现机器人自动导航的关键方法之一。在这项工作中,引入了一种基于强化学习的自动机器人导航方法。我们使用深Q网络(DQN)和近端策略优化(PPO)模型通过机器人与环境之间的持续互动以及具有实时反馈的奖励信号来优化路径计划和决策过程。通过将Q值函数与深神经网络相结合,深Q网络可以处理高维状态空间,从而在复杂的环境中实现路径计划。近端策略优化是一种基于策略梯度的方法,它使机器人能够通过优化策略功能来更有效地探索和利用环境信息。这些方法不仅可以提高机器人在未知环境中的导航能力,还可以增强其适应性和自学能力。通过多个培训和仿真实验,我们在各种复杂的情况下验证了这些模型的有效性和鲁棒性。
基于强化学习的自主机器人的研究
主要关键词



相关文件推荐