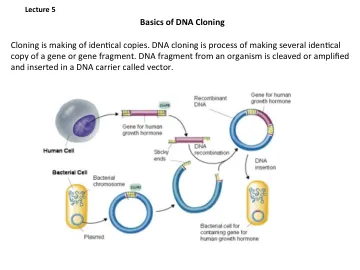
机构名称:
¥ 1.0
掩盖语言建模(MLM)作为预处理目标已在基因组序列建模中广泛采用。虽然审计的模型可以成功地作为各种下游任务的编码器,但在预处理和推理之间的分离转变会对性能产生不利影响,因为预处理的任务是映射[蒙版]对预测的标志,但是[mask]在下游应用程序中却没有[mask]。这意味着编码器不会优先考虑其非[蒙版]令牌的编码,而是在部署时间与MLM任务相关的工作,并在与MLM任务相关的工作中计算参数并计算。在这项工作中,我们根据掩盖的自动编码器框架提出了一个修改的编码器架构,旨在解决基于BERT的变压器中的这种低效率。我们从经验上表明,所产生的不匹配特别是在基因组管道中有害的,在基因组管道中,模型通常用于特征提取而无需微调。我们在Bioscan-5M数据集上评估了我们的方法,其中包含超过200万个独特的DNA条形码。与因果模型和通过MLM任务预测的因果模型和双向体系结构进行比较时,我们在封闭世界和开放世界分类任务中实现了可观的性能增长。
增强DNA基础模型以解决掩盖效率低下
主要关键词




相关文件推荐