
机构名称:
¥ 1.0
摘要。确保获得安全饮用水是一个基本的公共卫生优先事项。评估水质的传统方法是劳动力密集的,需要专门的设备,这对于连续监测可能是不可行的。本研究探讨了基于各种化学特性的机器学习模型来预测浸水性。具体来说,我们在存在阶级不平衡的情况下评估了逻辑回归和随机森林模型的性能,这是环境数据集中常见的问题。为了减轻这种情况,我们应用了合成的少数群体过采样技术(SMOTE)。我们的结果表明,在应用SMOTE之前,这两种模型均对多数类(非替代水)表现出很大的偏见,其精度为69.36%,Roc-AUC的准确性为0.63。然而,Smote的应用显着提高了该模型鉴定饮用水样品的能力,尤其是对于随机森林模型,该模型的准确度为67.07%,而Roc-auc的精度为0.64。相比之下,逻辑回归模型显示了SMOTE后的性能下降,这表明需要进一步优化或替代方法。本研究强调了解决机器学习任务中类不平衡的重要性,尤其是对于水质评估等关键应用程序。我们的发现表明,随机森林模型与Smote相结合,为预测浸水性提供了强大的解决方案。这些见解可以帮助环境科学家和公共卫生官员实施更高效,更准确的水质监测系统。未来的研究应探索更广泛的模型和高级技术,以进一步提高预测准确性。
机器学习方法的水力预测
主要关键词



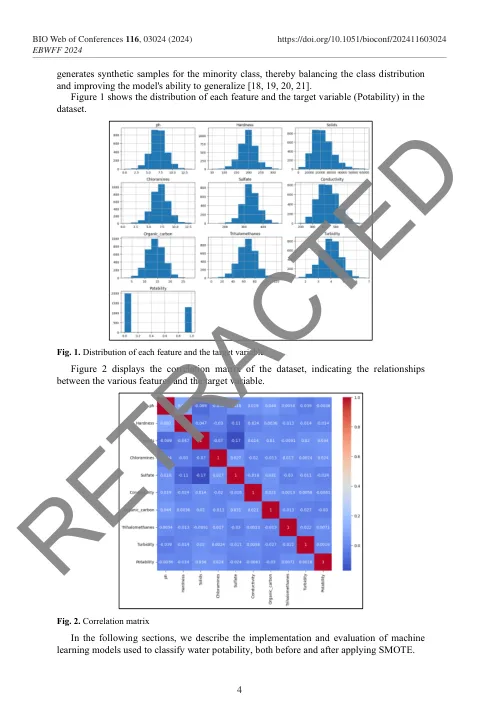

相关文件推荐





























