机构名称:
¥ 3.0
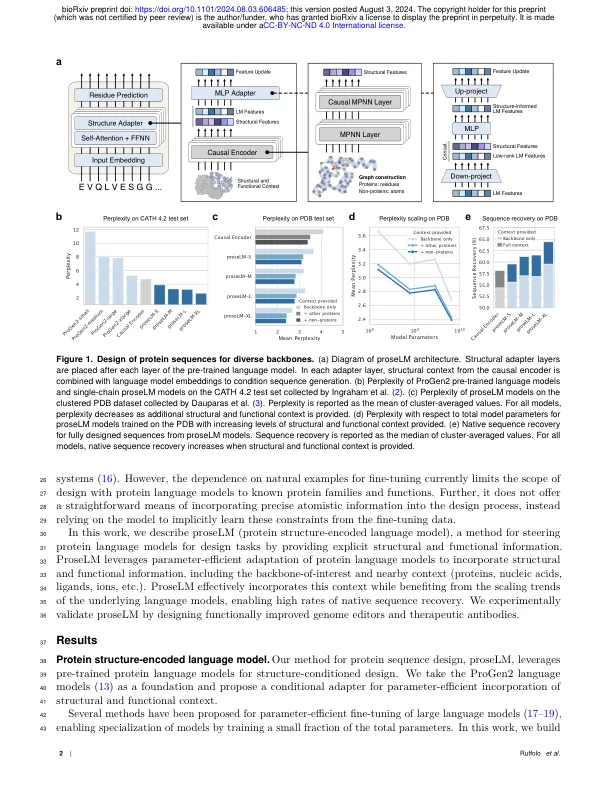
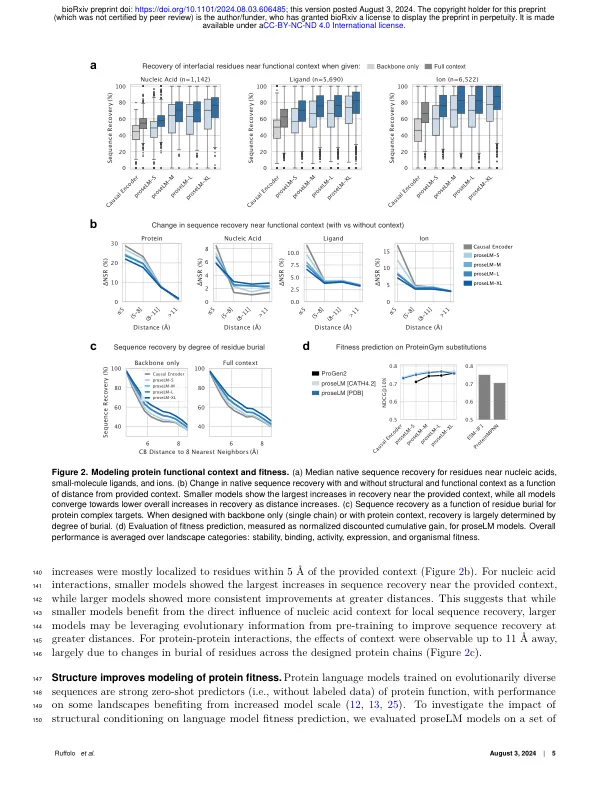
在实验确定的结构上训练的蛋白质设计生成模型已被证明可用于各种设计任务。然而,这种方法受到用于训练的结构的数量和多样性的限制,这些结构只占蛋白质空间的一小部分,且存在偏差。在这里,我们描述了 proseLM,这是一种基于蛋白质语言模型的适应性设计蛋白质序列的方法,以结合结构和功能背景。我们表明,proseLM 受益于底层语言模型的扩展趋势,并且添加非蛋白质背景(核酸、配体和离子)可在设计过程中将天然残基的回收率提高 4-5%,覆盖整个模型尺度。这些改进对于直接与非蛋白质背景交互的残基最为明显,最强大的 proseLM 模型可以以 >70% 的速率忠实地恢复这些残基。我们通过优化人类细胞中基因组编辑器的编辑效率,将碱基编辑活性提高了 50%,并通过重新设计治疗性抗体,获得了具有 2.2 nM 亲和力的 PD-1 结合剂,从而通过实验验证了 proseLM。
调整蛋白质语言模型以进行结构...
主要关键词



相关文件推荐