机构名称:
¥ 2.0
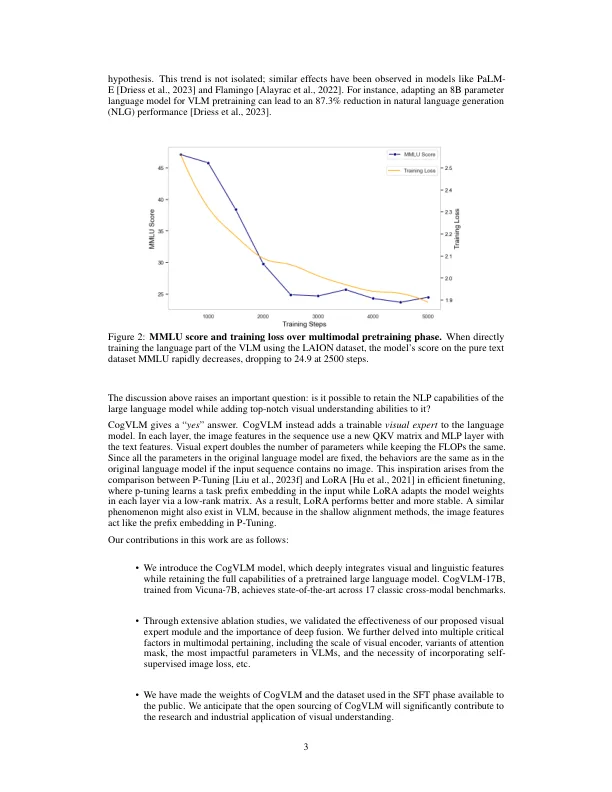
我们介绍了强大的开源视觉语言基础模型COGVLM。不同于流行的浅对齐方法,该方法将图像映射到语言模型的输入空间中,COGVLM通过注意力和FFN层中的可训练的视觉专家模块在冷冻预处理的语言模型和图像编码器之间存在差距。因此,COGVLM可以深入融合视觉语言功能,而无需牺牲NLP任务的任何性能。CogVLM-17B achieves state-of-the-art performance on 15 classic cross- modal benchmarks, including 1) image captioning datasets: NoCaps, Flicker30k, 2) VQA datasets: OKVQA, ScienceQA, 3) LVLM benchmarks: MM-Vet, MMBench, SEED-Bench, LLaVABench, POPE, MMMU, MathVista, 4) visual接地数据集:refcoco,refcoco+,reccocog,visual7w。代码和检查点可在GitHub上找到。
cogvlm:验证语言模型的视觉专家
主要关键词




相关文件推荐