
机构名称:
¥ 1.0
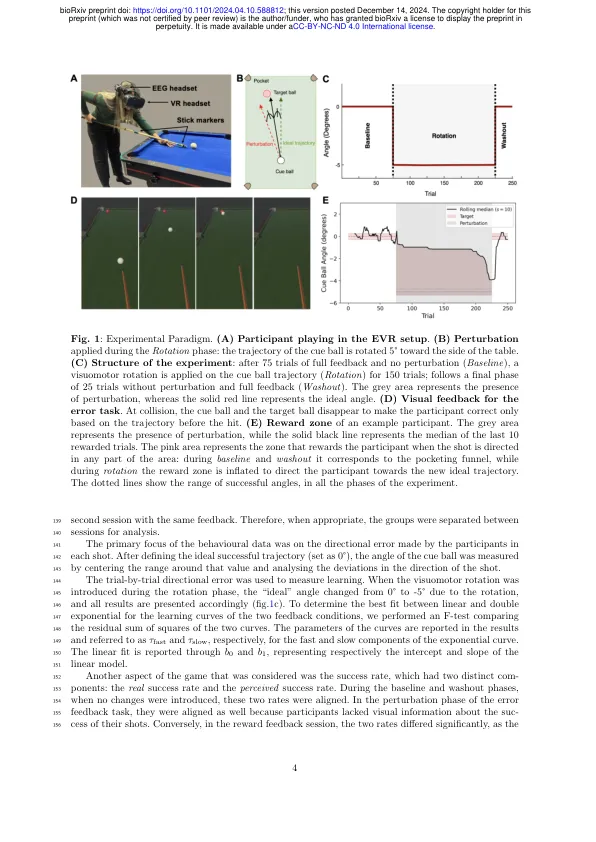
基于错误和基于奖励的运动学习机制在现实场景中同时发生,但传统上在实验室任务中通过反馈操作将它们区分开来。本研究通过将基于实验室的反馈操作应用于现实任务来检查这些机制的独特性。使用台球的具身虚拟现实 (EVR)——通过与实体台球桌、球杆和球的互动实现完整的本体感受——我们向现实任务中引入了视觉扰动。32 名参与者(12 名女性)进行了两次视觉运动旋转学习,一次带有错误反馈,一次带有奖励反馈。虽然未经训练的参与者通过错误反馈纠正了整个旋转,但通过奖励反馈只观察到部分纠正,突出了反馈机制对学习的影响。然而,奖励依赖性运动变异性、滞后 1 自相关衰减和试验间变异性衰减(所有基于奖励和技能学习的指标)在错误反馈会话中更高,这表明所提供的视觉反馈并没有专门参与特定的学习机制。运动后 beta 反弹 (PMBR) 是一种学习机制的大脑活动标记,对运动后 beta 反弹 (PMBR) 的分析表明,在奖励反馈期间 PMBR 会下降,但在错误反馈会话期间没有一致的趋势。这些发现支持了行为结果,表明虽然在错误条件下没有奖励反馈,但参与者仍然参与了基于奖励的学习。这项研究强调了运动学习过程的复杂性,并强调视觉反馈本身无法阐明现实世界中基于错误和基于奖励的机制之间的相互作用。
运动学习机制不会因反馈而改变
主要关键词




相关文件推荐





























