机构名称:
¥ 1.0
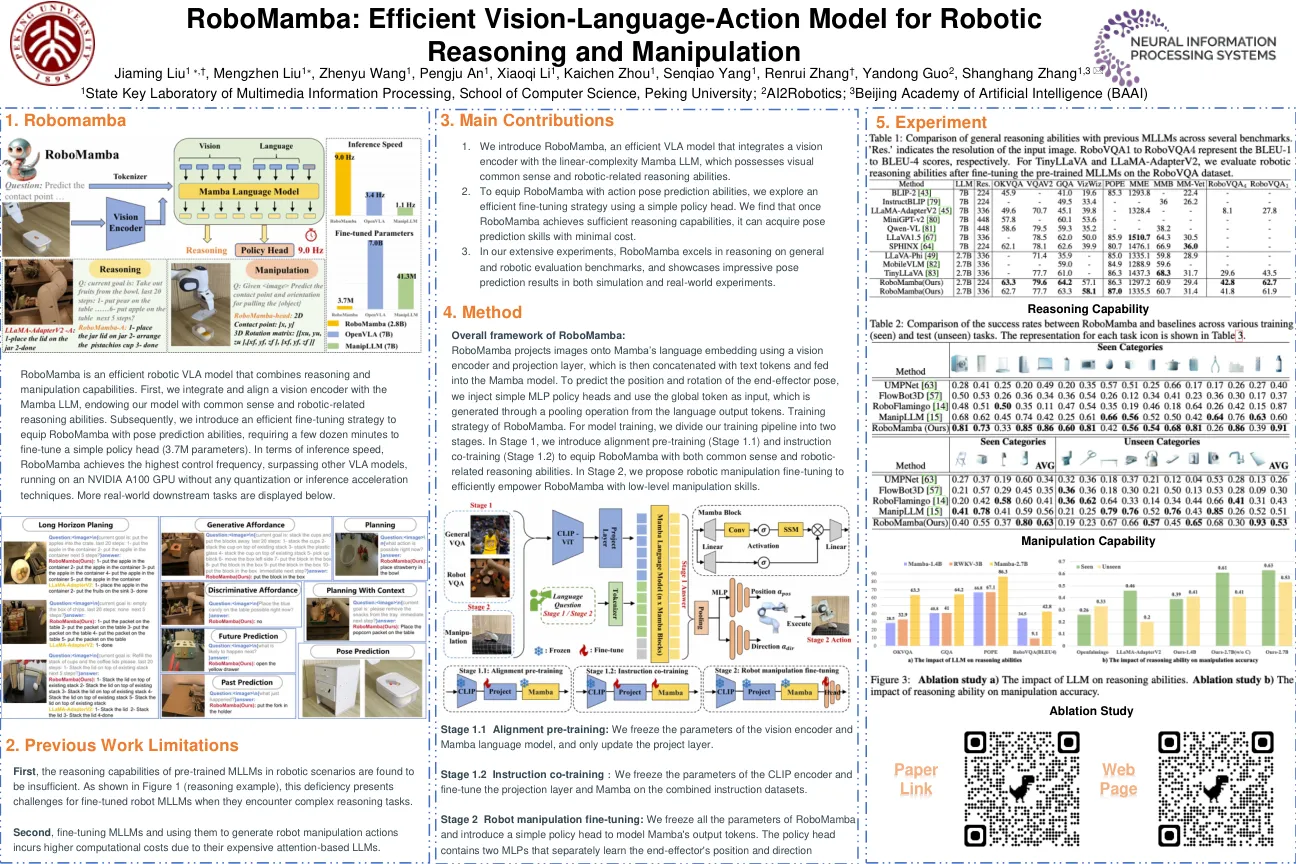
人工智能系统有各种形状和大小,从高度专业化的系统解决了人类思想无法接近的复杂概率,例如预测蛋白质的构象[21]到可以产生基于文本提示[40]的栩栩如生的高分辨率图像或视频的系统。然而,人类智能大多数机器智能的轴轴是多功能性的:解决位于各种物理环境中的各种任务的能力,同时巧妙地响应环境约束,语言命令和意外的扰动。也许可以在大型语言和视觉语言模型[1,48]中看到AI中这种多功能性的最切实进步:在网络上从大型且非常多样化的图像和文本进行预培训的系统,然后使用更精心策划的数据集进行精细调整(“对齐”),以诱发行为和响应的态度模式。尽管已经证明了这种模型可以表现出广泛的指导跟踪和解决问题的能力[53,27],但它们并不像人们那样真正地位于物理世界中,并且他们对身体互动的理解完全基于抽象描述。这样的方法是要向AI系统取得切实的进步,这些系统表现出人们所拥有的那种物理位置的多功能性,我们将需要在物理位置的数据上训练它们 - 也就是说,来自体现的机器人剂的数据。在自然语言[1]和计算机视觉[39]中,预先培训的多任务数据的通用基础模型倾向于优于狭义和专业的可以任务执行各种机器人行为的灵活和通用模型具有巨大的实践后果,但它们也可能为当今机器人学习面临的一些最艰巨的挑战提供解决方案,例如数据的可用性,概括和鲁棒性。
π0:通用机器人控制的视觉语言流动流模型
主要关键词





相关文件推荐