机构名称:
¥ 1.0
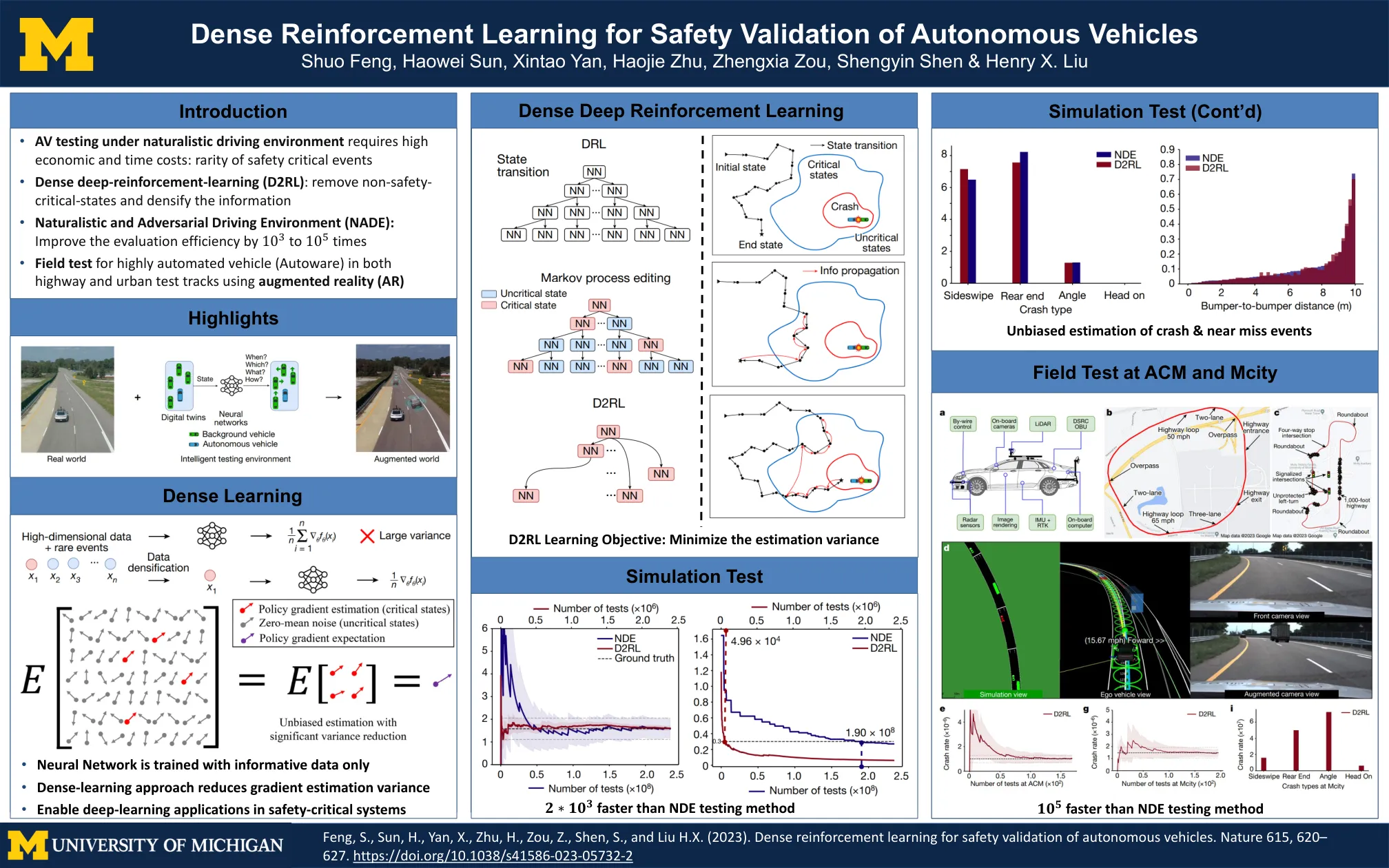
自动驾驶汽车赛车引起了广泛的兴趣,因为它在极限的自动驾驶中具有巨大的潜力。基于模型和基于学习的方法已被广泛用于自主赛车。但是,基于模型的方法在仅可用局部感知时无法应对动态环境。作为比较,基于学习的方法可以在本地感知下处理复杂的环境。最近,深度强化学习(DRL)在自主赛车上越来越受欢迎。DRL通过处理复杂情况并利用本地信息来优于传统的基于学习的方法。DRL算法,例如近端政策算法,可以在自动驾驶竞争中的执行时间和安全性之间达到良好的平衡。但是,传统DRL方法的训练结果在决策中表现出不一致的正确性。决策中的不稳定引入了自动驾驶汽车赛车的安全问题,例如碰撞到轨道边界中。所提出的算法能够避免碰撞并提高训练质量。在物理发动机上的仿真结果表明,所提出的算法在避免碰撞中的其他DRL算法优于其他DRL算法,在急剧弯曲期间实现更安全的控制以及多个轨道之间的较高训练质量。关键字:自动驾驶汽车赛车,本地规划,近端政策优化,平衡奖励功能。
自动驾驶汽车赛车的平衡奖励启发的增强学习
主要关键词





相关文件推荐