机构名称:
¥ 1.0
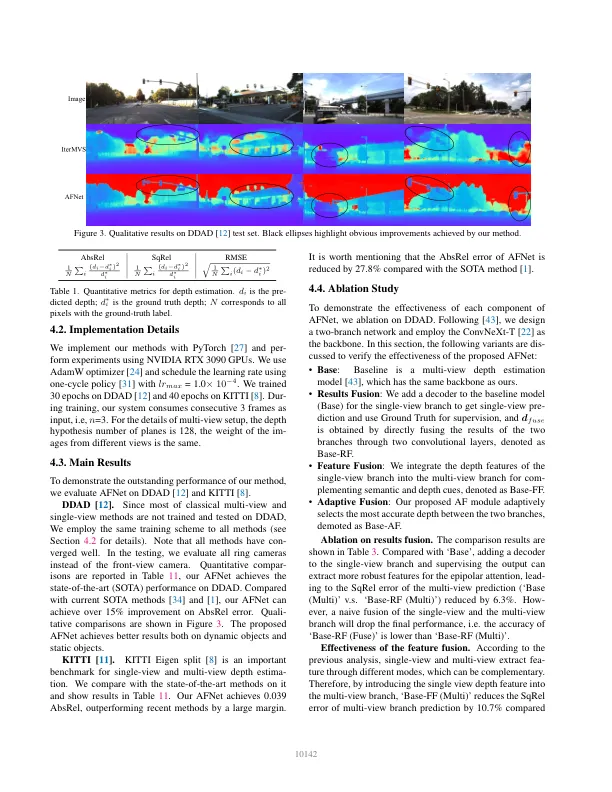
来自图像的深度估计是具有广泛应用的计算机视觉中的一个长期问题。对于基于视觉的自动驾驶系统,感知深度是理解道路对象和建模3D环境图的相关性的不可或缺的模块。由于深度神经网络用于求解各种视觉概率,因此基于CNN的方法[2-5,13,39 - 42,44,44,46,48,52]主导了各种深度基准。根据输入格式,它们主要将其分为多视图深度估计[3,13,23,26,44,45,51,53]和单视深度估计[14 - 16,19,37,38]。多视图方法估计深度的假设,即给定的深度,相机校准和摄像头姿势,这些像素应相似。他们依靠表现几何形状来三角形高质量深度。但是,多视图方法的准确性和鲁棒性在很大程度上依赖于相机的几何配置以及视图之间匹配的对应关系。首先,需要足够翻译相机以进行三角度。在自主驾驶的情况下,汽车可能会停在交通信号灯处或不移动而不移动,这会导致故障三角剖分。此外,多视图方法遭受动态对象和无动电区域的影响,它们在自动驱动方案中无处不在。另一个问题是对移动车辆的施加优化。在存在的大满贯方法中不可避免地噪声,更不用说具有挑战性和可取的情况了。具体来说,我们提出了一个两个分支网络,即例如,一辆机器人或自动驾驶汽车可以在不重新校准的情况下部署多年,原因是嘈杂的姿势。相比之下,作为单视图方法[14 - 16,19,37,38]依赖于对场景的语义理解和透视投影提示,它们对无纹理区域,动态对象,而不是依赖相机姿势更为易用。但是,由于规模歧义,其性能仍然远非多视图方法。在这里,我们倾向于考虑是否可以很好地结合两种方法的好处,以实现自主驾驶场景中的稳健和准确的单眼视频深度估计。尽管已经在先前的工作中探索了基于融合的系统[1,9],但他们都假定了理想的相机姿势。结果是融合系统的性能甚至比单视深度估计的噪声姿势还差。为了解决这个问题,我们提出了一个新型的自适应融合网络,以利用多视图和单视图方法的优势,并减轻其缺点,以保持高度的精度,并在噪声姿势下提高系统的影响力。一个靶向单眼深度提示,而另一个则利用多视图几何形状。两个分支都预测了深度图和置信图。补充语义提示和边缘细节在多视图分支的成本汇总中丢失了
自动驾驶的单视图和多视图深度的自适应融合
主要关键词




相关文件推荐